Cloud
Full-Stack Observability czyli jak skutecznie monitorować aplikacje, sieć i sprzęt, zaczynając od naszego Data Center a kończąc na chmurze
Nieoptymalne działanie naszej aplikacji czy choćby krótkotrwały brak dostępu do niej przekłada się na realne straty w biznesie. Przyspieszona cyfryzacja procesów biznesowych, migracja aplikacji do architektury natywnej dla chmury oraz jej uruchomienie w środowisku wielochmurowym potęguje ilość przetwarzanych danych, procesów oraz zależności, które należy odpowiednio monitorować i kontrolować.
Z pomocą przychodzi rozwiązanie Full-Stack Observability (FSO) od Cisco, które centralizuje i koreluje informacje dotyczące wydajności, dostępności oraz powiązań występujących w naszym (i nie tylko) środowisku aplikacyjnym, sieciowym, sprzętowym oraz chmurowym.
Dziś przyjrzymy się poszczególnym elementom wchodzącym w skład Full-Stack Observability i ich przeznaczeniu. Docelowo platforma zapewnia to, co dla biznesu jest najistotniejsze, a dla działów IT wskazuje najważniejsze kierunki rozwoju środowiska czyli:
- Na bieżąco poprawia jakość obsługi i satysfakcję użytkowników, poprzez ciągłe monitorowanie działania kodu aplikacji, warstwy komunikacyjnej oraz zasobów IT. Dzięki możliwości monitorowania niezależnych od nas usług (np. od zewnętrznych dostawców) pozwala na szybkie wykrycie awarii i zapewnienie ciągłego dostępu użytkowników do aplikacji z dowolnego miejsca na świecie.
- Pozwala na korelację tych działań ze wskaźnikami biznesowymi, co przekłada się na utrzymanie kluczowych metryk wydajnościowych na żądanym poziomie, a dodatkowo umożliwia oszacowanie zapotrzebowania na zasoby w przyszłości i pomaga w podjęciu decyzji, w jakim kierunku należy rozwijać środowisko.
Całościowe spojrzenie na aplikację i środowisko
Zanim jednak przejdziemy dalej, rozważmy hipotetyczną sytuację: klient korzystający z naszej aplikacji mobilnej nie może dokonać płatności za towar/usługę – kto ma problem – my czy klient? Jeżeli nie zareagujemy dostatecznie szybko, pójdzie do konkurencji a za nim następni, których ten problem również będzie dotyczył. A my musimy jak najszybciej zidentyfikować miejsce, gdzie jest umiejscowiony. Czy dotyczy on aplikacji mobilnej, połączenia sieciowego klienta, usługi w chmurze, serwera obliczeniowego, bazy danych, wywołania API do usługi przetwarzania transakcji… czy czegoś innego? Nie możemy rozwiązać problemu, jeśli nie wiemy, gdzie on wystąpił. Ustalenie, jak rozwiązać problem z wydajnością lub bezpieczeństwem wymaga zarówno specjalistycznej wiedzy o danej domenie, jak i całościowego spojrzenia na aplikację i środowisko, które pozwoli zobaczyć, jak jeden błędnie działający element wpływa na funkcjonowanie całego systemu.
FSO pomaga dokładnie zrozumieć, w jaki sposób przebiega obsługa użytkowników, niezależnie czy korzystają z aplikacji mobilnej czy webowej. Wykrywa wszystkie komponenty wchodzące w skład ekosystemu aplikacji, pokazuje ich wzajemne powiązania oraz bada wydajność. Pomaga określić, które elementy w kodzie aplikacji należy usprawnić, aby poprawić czas odpowiedzi na zapytania, a także pozwala wychwycić moduły mogące w przyszłości sprawiać problemy w obliczu zwiększonego ruchu, zanim jeszcze one wystąpią. FSO odnajduje błędy w aplikacji nawet w tak skrajnych przypadkach, gdy dotyczą one kilku procent klientów, a dzięki stałej obserwacji całego środowiska uczy się jego zachowania, co przekłada się na późniejsze błyskawiczne wychwytywanie wszystkich anomalii w jego funkcjonowaniu.
W skład Full-Stack Observability wchodzą aktualnie trzy elementy:
✔ Cisco AppDynamics
✔ Cisco ThousandEyes
✔ Cisco Intersight Workload Optimizer
Poniżej omawiamy każdy z nich.
AppDynamics
Podstawową funkcją AppDynamics jest monitorowanie wydajności aplikacji (APM – Application Performance Monitoring). Narzędzie to inteligentne centrum dowodzenia działające w czasie rzeczywistym, reagujące na zdarzenia zaobserwowane w środowisku aplikacyjnym, zaczynając od urządzeń końcowych użytkowników, przez usługi w naszym Data Center, aż do serwisów w chmurze publicznej. Co istotne, jest świadome struktury procesów biznesowych pozwalając na analizę oraz raportowanie kluczowych dla biznesu metryk oraz uczy się domyślnych parametrów działania środowiska. W momencie wykrycia odchyleń automatycznie powiadomi o zaistniałej sytuacji i np. w przypadku, gdy jedna z aplikacji w stosie zacznie niedomagać, AppDynamics potrafi wskazać źródło problemu, nawet do konkretnej linii kodu konkretnego wywołania API. Dalej, jeśli dany element sieci stanie się wąskim gardłem dla systemu, wygeneruje alert, który albo potwierdzi to co nasze doświadczenie nam podpowiada odnośnie przyczyny, albo nakieruje na inne wskazówki, pozwalając szybko rozwiązać problem.
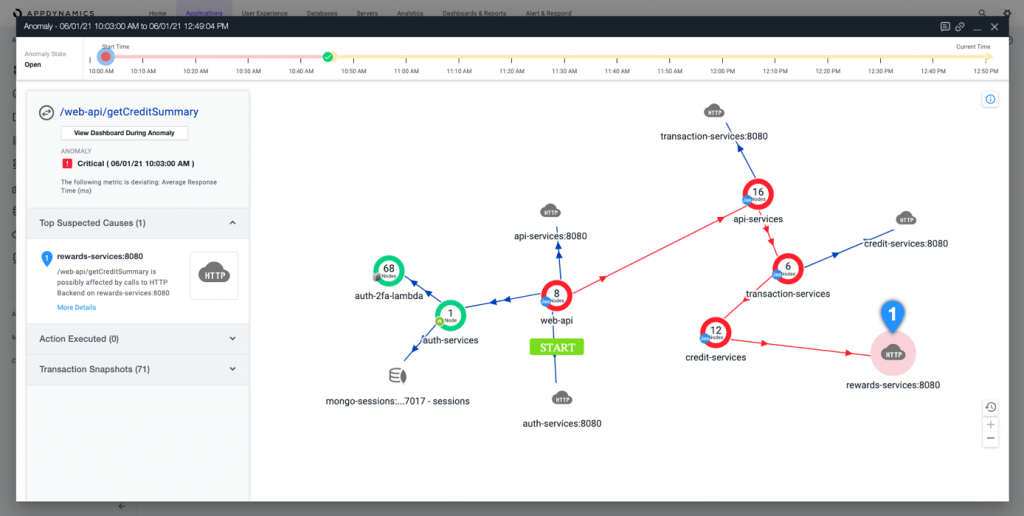
AppDynamics to potężne narzędzie dla programistów, inżynierów DevOps oraz SRE, umożliwiające szybkie zrozumienie wymagań jakie aplikacje stawiają wobec warstwy sieciowej oraz podpowiadające jak dostosować infrastrukturę, by zapewnić ich płynne, bezawaryjne działanie. Dostarcza również mechanizmy korelujące i mapujące zebrane metryki wydajnościowe na biznesowe wskaźniki KPI, co w rezultacie pozwala na lepsze zarządzanie funkcjonowaniem środowiska.
Integrated Solutions od 2021 roku jest oficjalnym, certyfikowanym Partnerem AppDynamics. Pomagamy naszym Klientom w planowaniu, wdrażaniu i utrzymaniu rozwiązania, a także w jego rozwoju w środowisku.
ThousandEyes czyli Tysiąc Oczu
Nie będzie przesadą stwierdzenie, że ThousandEyes rozświetla ścieżki, którymi podąża Wasza aplikacja przez globalne łącza, również poza siecią korporacyjną. ThousandEyes pozwala zobaczyć na żywo połączenia pomiędzy infrastrukturą, centrami danych oraz usługami od zewnętrznych dostawców. Dostarcza narzędzia umożliwiające nie tylko monitorowanie ruchu sieciowego pomiędzy wybranymi dwoma procesami (np. aplikacją typu front-end a bazą danych w back-endzie), ale również wydajności w sieci Internet pomiędzy dwoma praktycznie dowolnymi, istotnymi dla nas punktami w globalnej infrastrukturze (przy wykorzystaniu dedykowanych agentów). ThousandEyes zapewnia także syntetyczne testy symulujące ruch generowany przez użytkownika końcowego, dostarczające metryki między innymi takie jak czas odpowiedzi, czas ładowania strony www oraz inne kluczowe wskaźniki wydajności, jakże przydatne podczas testów aplikacji, poprzedzających jej wdrożenie produkcyjne. Takie testy syntetyczne działają w oparciu o globalnych agentów ThousandEyes, pokazując jak będzie funkcjonowała aplikacja w danym regionie. Biorąc pod uwagę udostępnione API możemy zautomatyzować takie testy, by były wyzwalane w momencie zmian konfiguracji sieci czy wypchnięciu nowego kodu do repozytorium.
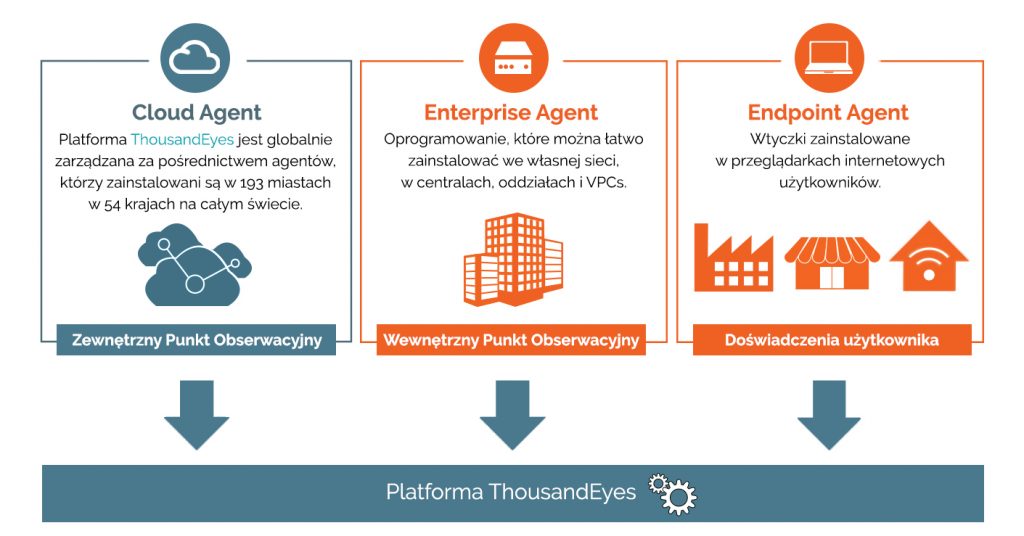
Integracja rozwiązań ThousandEyes oraz AppDynamics daje nam pełny wgląd w środowisko aplikacyjno-sieciowe, pozwala uniknąć wielu problemów konfiguracyjnych czy też związanych z nowo wprowadzanym kodem aplikacji. Dzięki temu tandemowi możemy bardzo precyzyjnie określić miejsce, w którym wystąpił błąd, co czyni go niezbędnym rozwiązaniem w pracy inżynierów sieci, DevOps czy SRE.
Intersight Workload Optimizer
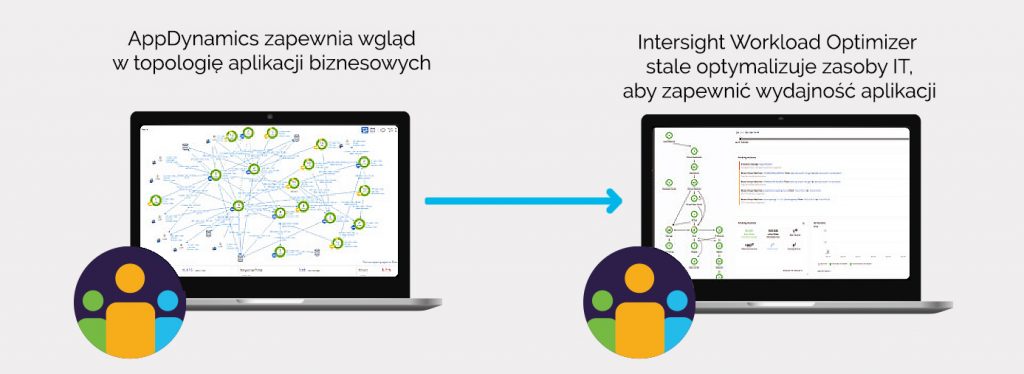
Intersight Workload Optimizer to trzeci element platformy Full-Stack Observability. Sam Intersight określany jest przez Cisco jako Cloud Operations Platform, pozwala na inicjowanie oraz kontrolę przebiegu procesów dotyczących infrastruktury obliczeniowej, sieciowej czy składowania danych, zaczynając od serwerów w naszej serwerowni, kończąc na klastrach kubernetesowych od dostawców chmurowych.
Intersight Workload Optimizer ułatwia strojenie wydajnościowe w zarządzanym środowisku. Rozwiązanie wykorzystuje sztuczną inteligencję do analizy zebranych danych telemetrycznych oraz formułowania zaleceń dotyczących konfiguracji zasobów. Co istotne, integruje się też z narzędziem powoływania zasobów Hashicorp Terraform, co znacznie ułatwia wprowadzanie zmian w środowisku. Całość prac można przeprowadzić prosto z konsoli lub – jeśli zajdzie taka potrzeba – można wykorzystać dostępny interfejs API do wywoływania wymaganych zadań.
Full-Stack Observability – razem lepiej
Wszyscy jesteśmy świadomi tego, że liczba aplikacji i procesów biznesowych nie dość, że rośnie lawinowo, to do ich obsługi potrzebni są eksperci z unikalną wiedzą, często w wąskich dziedzinach. Tradycyjnie każdy z nich ma własny zestaw narzędzi ułatwiający im wykonywanie codziennych zadań, często mocno podzielonych z perspektywy przydzielonego zakresu obowiązków i nie do końca świadomych tego, co dzieje się w innych miejscach. I tak nie zawsze zwiększenie mocy obliczeniowej będzie poprawnym rozwiązaniem problemu błędnego kodu, który i tak nie będzie działał optymalnie.
Full-Stack Observability podziela wizję DevOps – pełnej współpracy pomiędzy różnymi działami, by konkretne cele biznesowe były realizowane świadomie przez wszystkich uczestników. Dlatego właśnie kompleksowa strategia monitorowania jest tak skuteczna – pokazuje elementy sprawiające problem a jednocześnie pozwala na sprawną identyfikację tych obszarów, którymi należy zająć się w pierwszej kolejności, by skutecznie realizować cele biznesowe, zostawiając mniej istotne zadania na później.
Integrated Solutions jako wieloletni partner Cisco a także certyfikowany partner AppDynamics chętnie pomoże w rozpoczęciu pracy z Full-Stack Observability w środowiskach zarówno deweloperskich jak i produkcyjnych naszych klientów. Wesprzemy w przeprowadzeniu instalacji testowej, wdrożeniu produkcyjnym, a także późniejszym rozwoju platformy, by jak najlepiej wspomagała w rozwoju i zabezpieczeniu prowadzonego biznesu.
Zapraszamy do kontaktu.